Lilli
Building Trust in GenAI through Clarity in Data
Duration
Oct. 2023 - Dec. 2023
Role
Senior Product Designer
Team
5 Product managers
3 Data engineers
3 Leaderships
Context
Lilli is the firm’s first GenAI tool, designed to be the single source of accurate, unbiased, and high-quality information. Its mission is to alleviate the pain points of colleague consultants by reducing the time spent on research, allowing them to shift their focus on delivering impactful insights to clients.
19+ Microsites
39+ External database
6+ Different types of data
My mission was to ensure a user-centered approach to prioritize the data ingestion roadmap, map use cases for engineered queries, and enhance UX/UI to deliver trustworthy and user-centric answers.

Problem
The problem was twofold:
Lilli was producing irrelevant answers due to a lack of understanding of users' intent, which damaged trust in the product.
The data ingestion team lacked prioritization and use case mapping, leading to low-quality or irrelevant results. This resulted in longer working hours and low yield for the team.
“The answer missed a huge portion of practice knowledge and came with very generic ones”
“I tried asking about the evaluation topic but it referred me to some experts”
Deeper-Dive into Problems
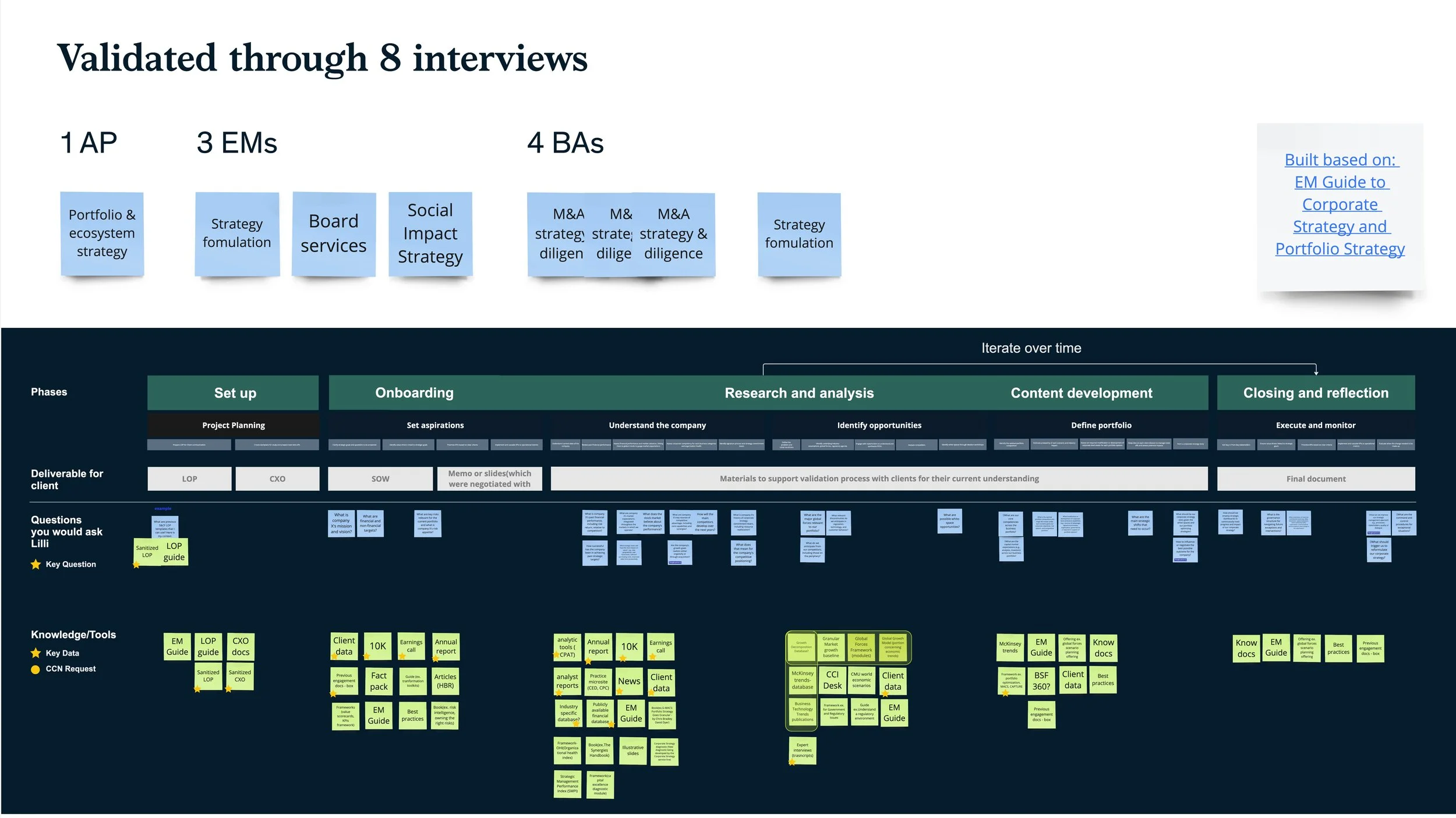
To better understand the problem and user needs, I conducted 15 interviews. These focused on data usage frequency, the types of questions users ask, their expectations for various data types, how they process information, and their pain points.
Key insights:
Due to the nature of our users' work, they emphasized the importance of cross-checking sources.
Our users prioritize accuracy over a breadth of sources.
Users often return to the same data sources but search with varying levels of depth.
Users not knowing which data ingested into Lilli, limit their search.


Solutions
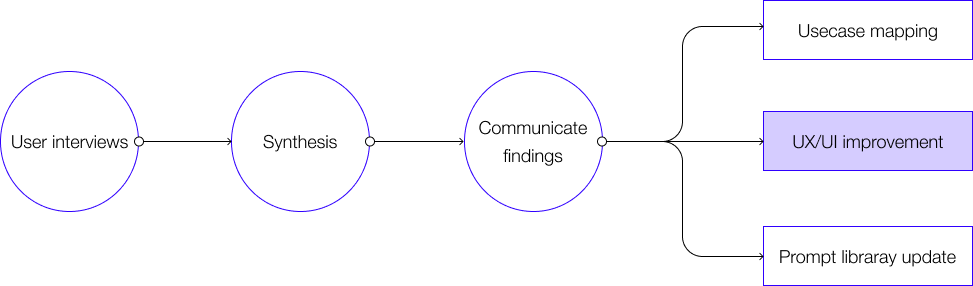
These insights were communicated throughout the larger team and had a significant impact in three areas, where I was actively in charge:
Redesigned source interactions for clarity and transparency
Mapped use cases for 8 different data sources for ingestion
Gathered and shipped user-generated prompts for accuracy
Updated the prompt library
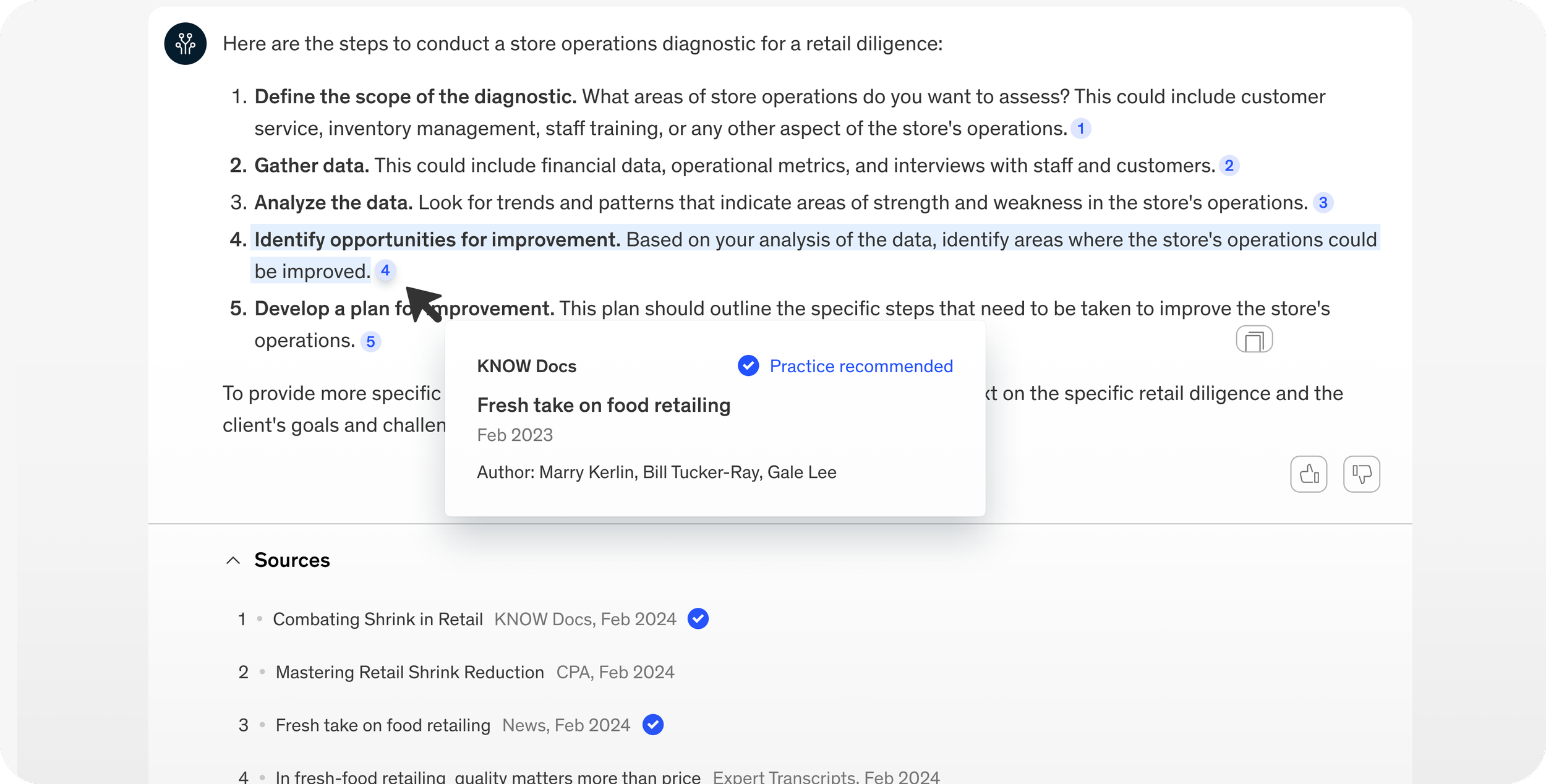
UX/UI Improvement: Redesigning Source Interactions
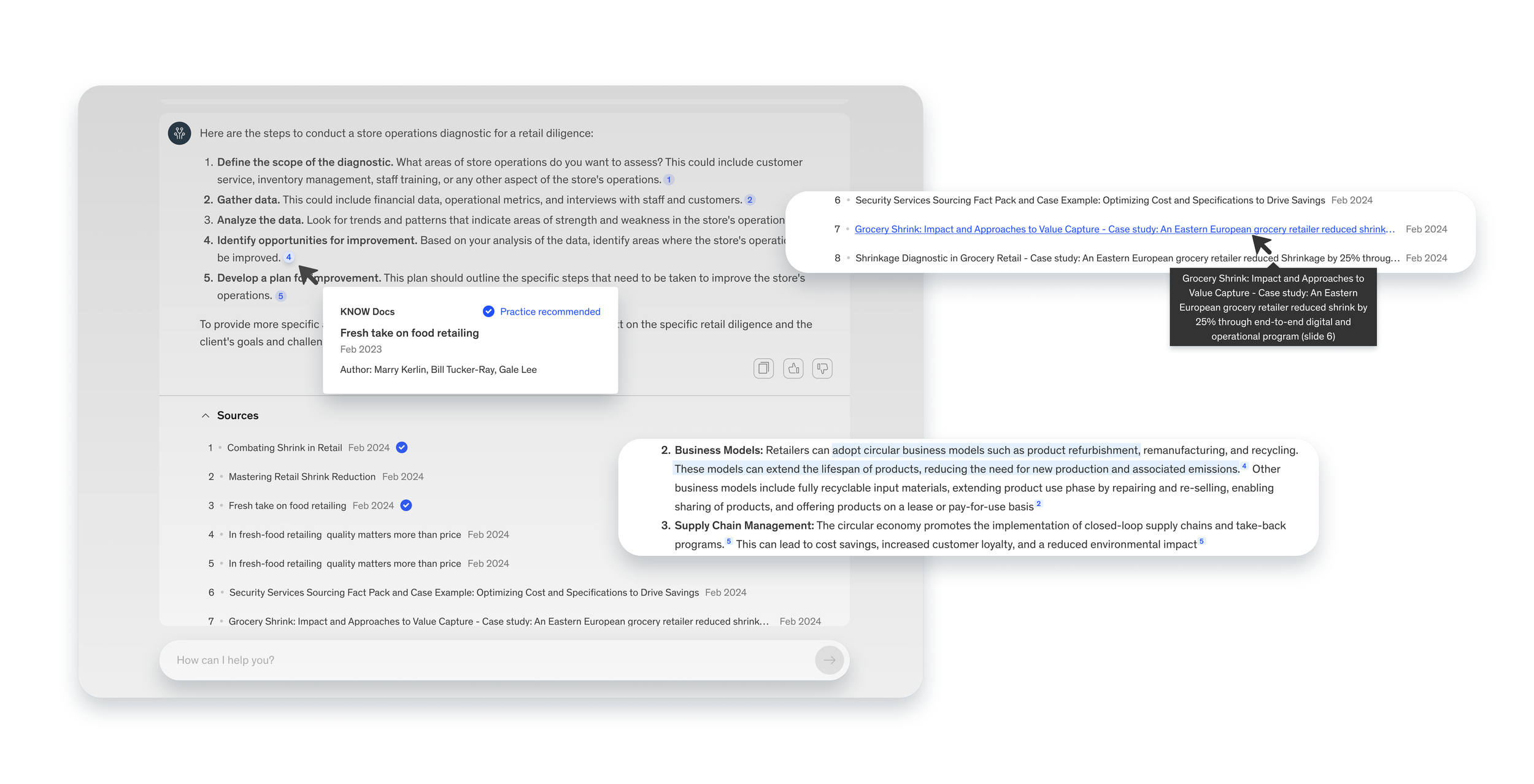
In-line citation & quick source info.
To enhance the discoverability and credibility of the information provided, designed footnote-style citations in its responses.
Allow single click to the original source
Hover-over tooltip to show quick view
Highlights on sections
Lilli highlights which portion of the response is derived from each source, making it easy for consultants to trace and verify the origin of the information.
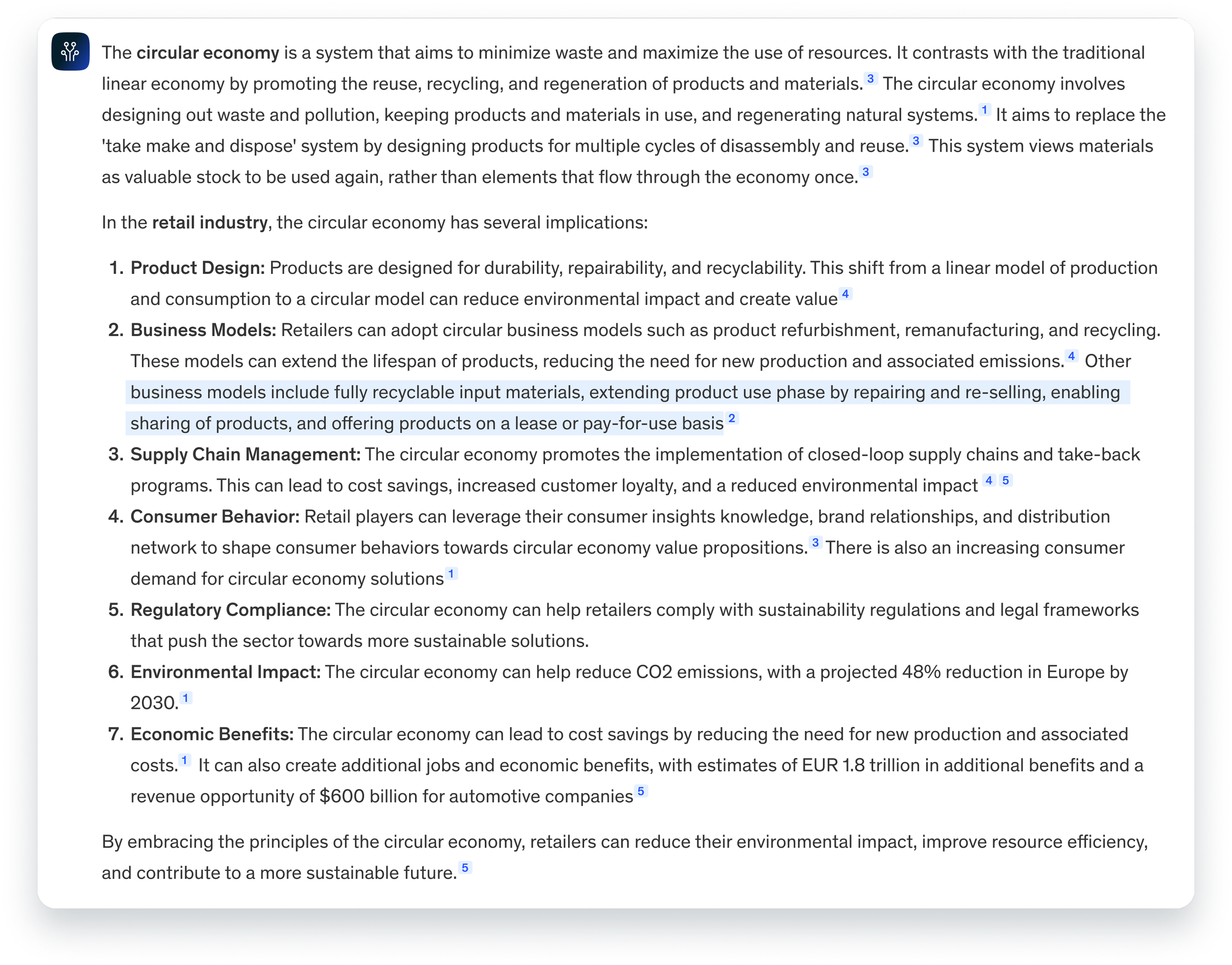
One source, one section
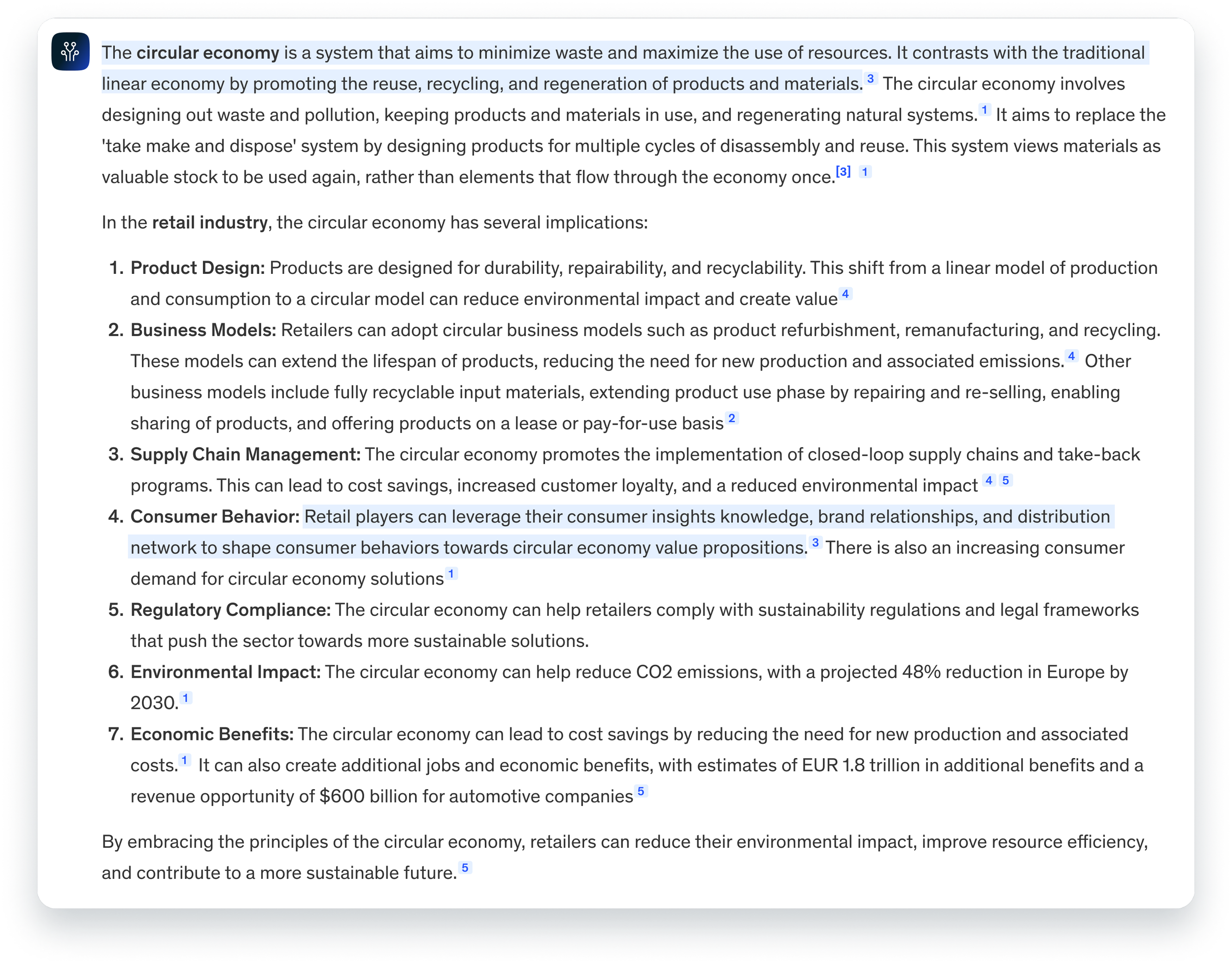
One source, multiple sections
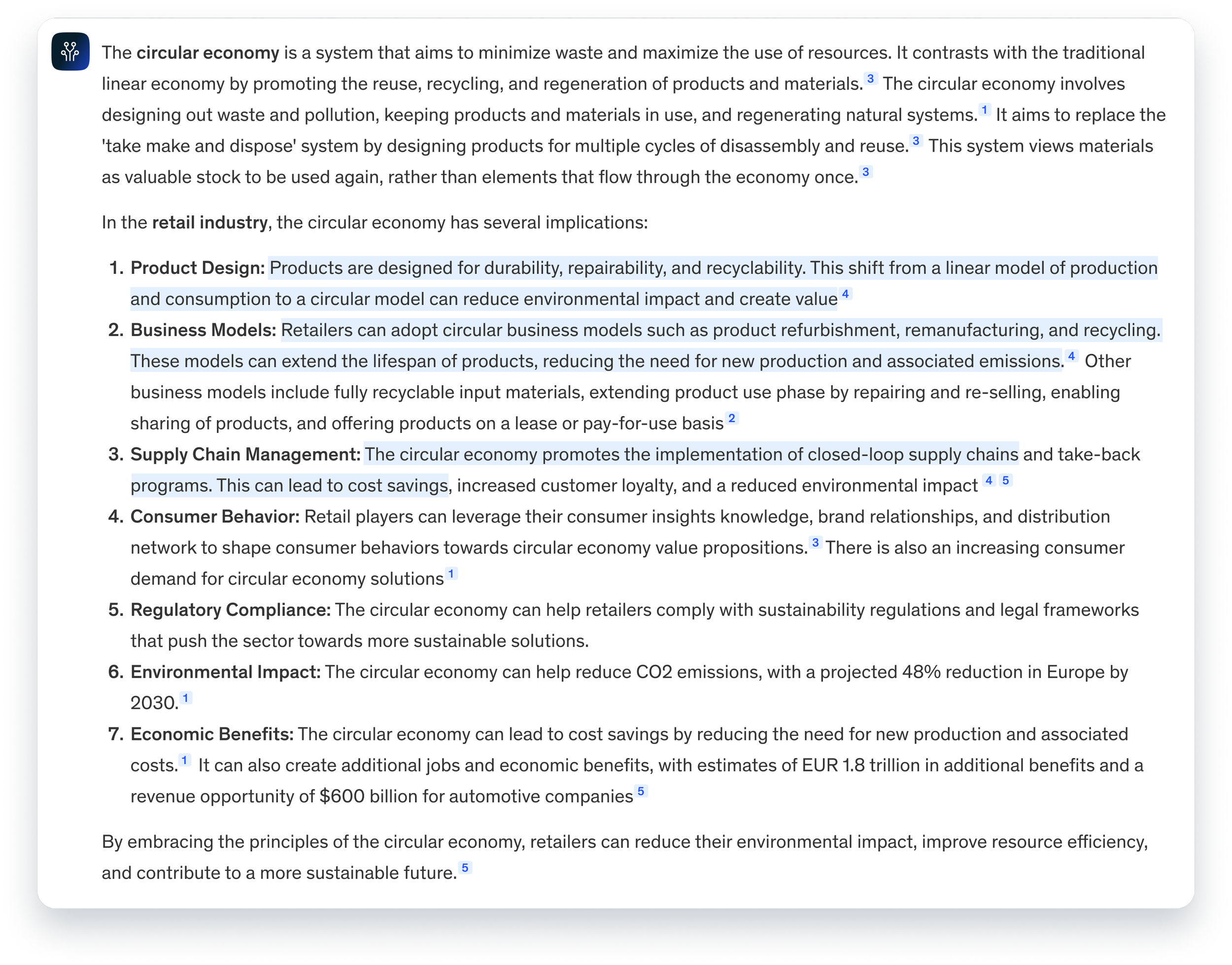
One section, multiple sources
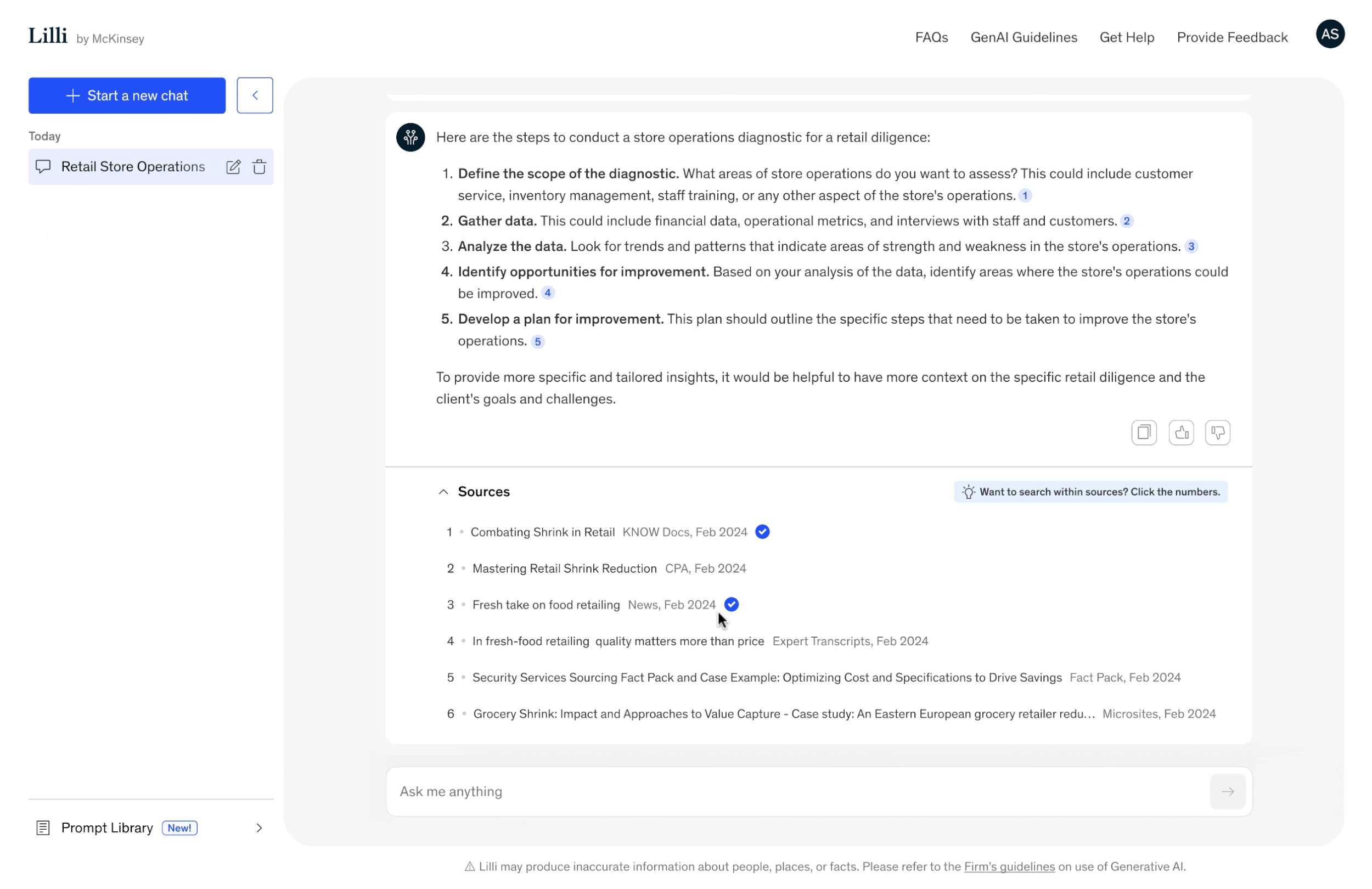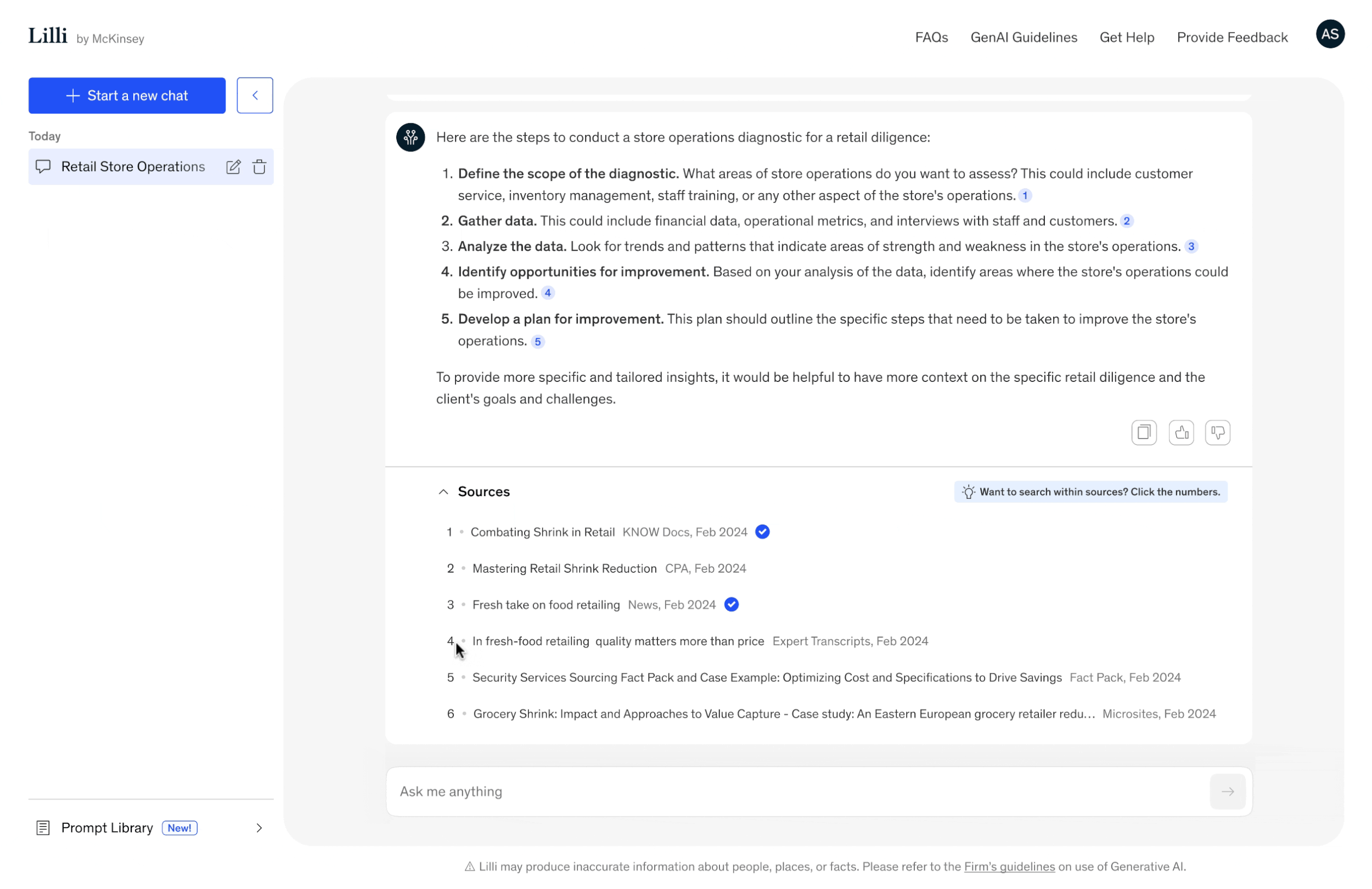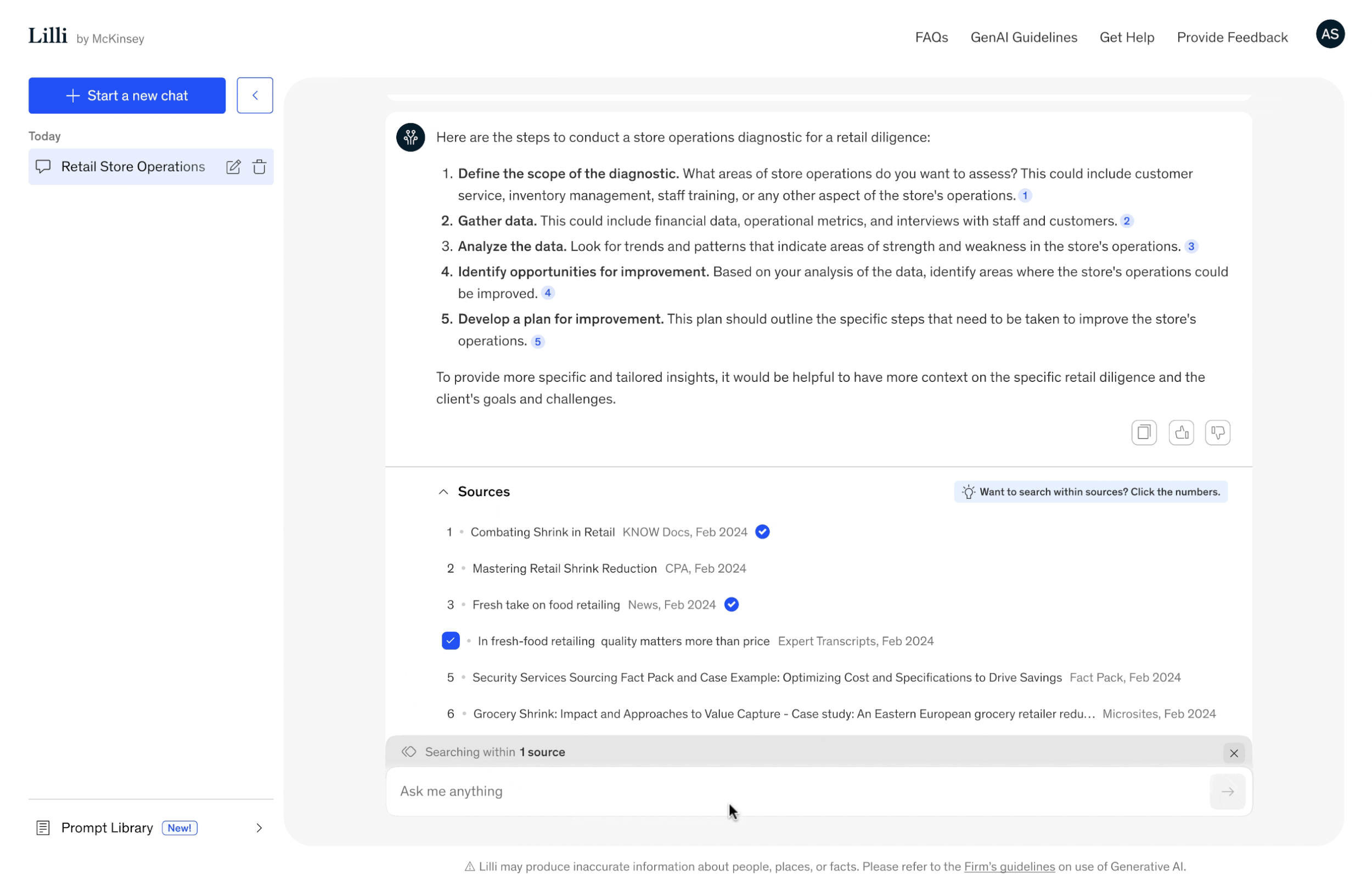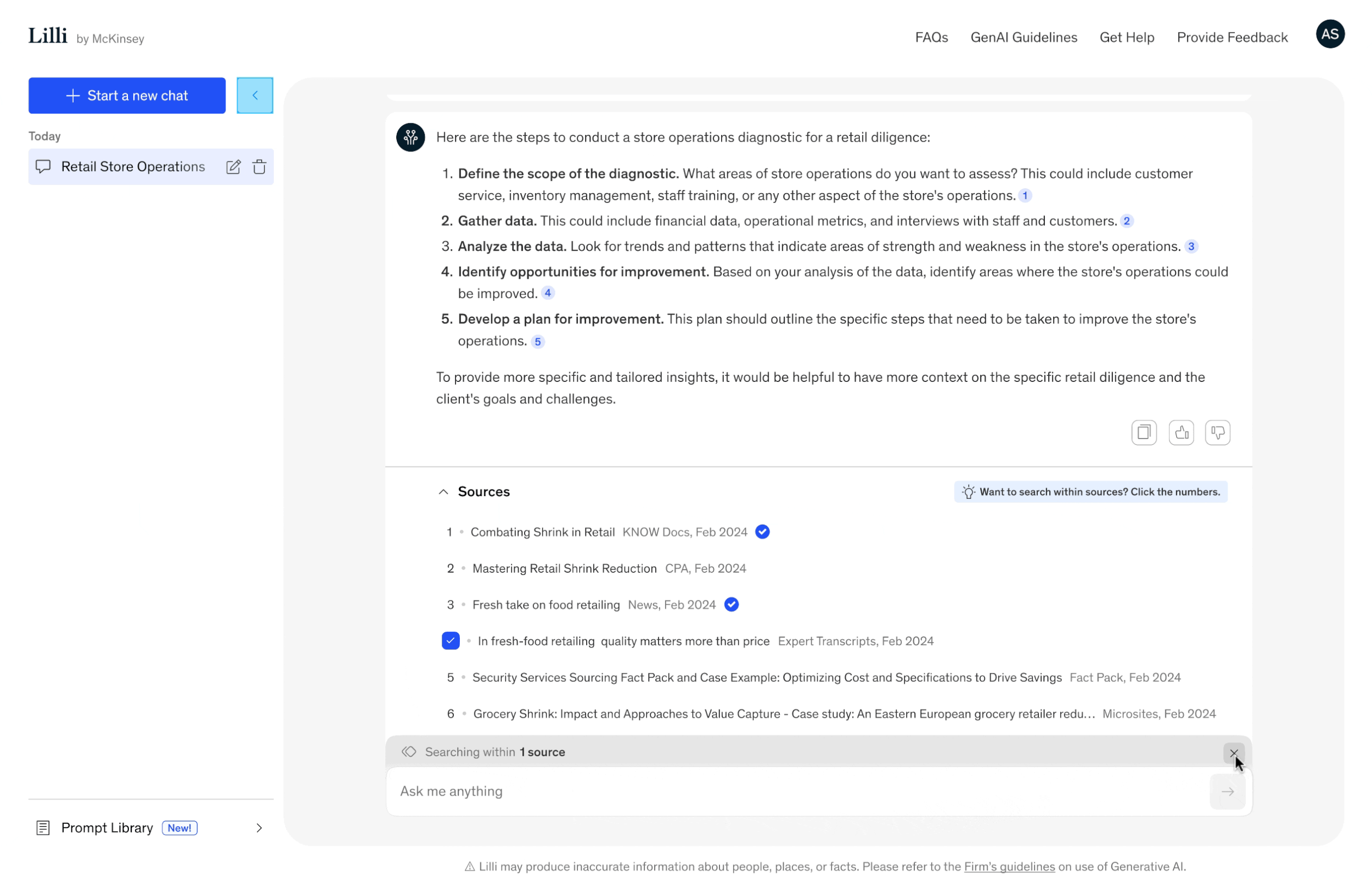
Search within selected sources
Our users often use the same source during client engagements but with varying levels of depth.
Based on this insight, we developed a feature that fits their needs: the ability to search within a selected source.
This enables more in-depth research, allowing users to explore the content with greater precision and relevance.
Increasing Accuracy and Relevance through Use Case Mapping
At the firm, multiple teams own various types of data, each organized differently, without fully understanding how consultants use it. Engaging these teams as stakeholders helped map their use cases and intent, enabling Lilli to surface the right, focused data sets effectively.

Mapped use cases for 8 different types of data sources
Collected actual user prompts for data ingestion
Based on initial research and additional studies, we collaborated with eight external teams to accurately capture use cases for each data source for intent mapping and response design.
Users shared that Lilli often misunderstood queries and provided irrelevant answers. To address this, we gathered real user queries through interviews, re-mapped intents, and refined test prompts to better reflect actual queries for data engineering.
Prioritizing High-Value Data
7 important
& frequently used data sources
11 non-essential data sources
Maximum shelf-life 3 years
Contributed the roadmap with these findings
The team was moving quickly, compromising our work-life balance and the quality of our output. We needed to prioritize data sources effectively. To address this, we conducted additional surveys to gather quantitative insights and shared the findings with senior leadership. This helped narrow down data sources.


Wrap-up
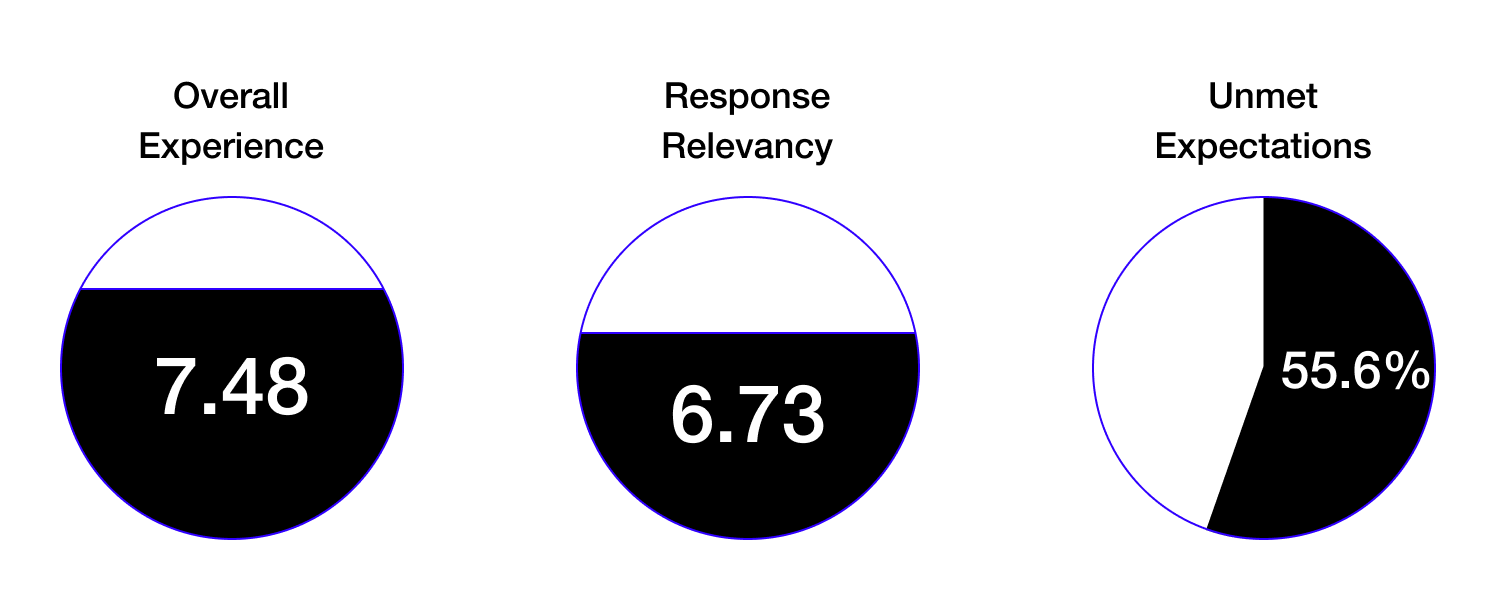
Within two weeks of releasing features and improvements, we achieved user engagement, increased satisfaction with the overall experience, and improved response relevance.
761K
Clicks on source links
7.48→8.64
User overall experience
6.73→8.1
Response relevancy